2.3* 差分隐私定义补充说明
1、贝叶斯解释
令 X=(X1,...,Xn)∈Xn 为随机变量,该随机变量是根据对手对数据集的“先验知识”而产生的分布。并令 X−i=(X1,...,Xi−1,⊥,Xi+1,...,Xn) 为去除掉第 i 个人的数据的数据集(或将该人的数据替换为 dummy value)。
假设 M:Xn→Y 是 ε-差分隐私的,令 y∈Y 为任意可能的输出。则:对于每一个 xi∈X,有:
Pr[Xi=xi∣M(X)=y]∈e±ε⋅Pr[Xi=xi∣M(X−i)=y]
2、差分隐私定义的注解
1、在 定义 2.3 提及了差分隐私定义的变体形式。
数据库 x 视为来自全集 X 的记录的集合。用它们的直方图表示数据库通常会很方便:x∈N∣X∣ ,其中每个项 xi 表示数据库 x 中类型 i∈X 元素的数量。则,其相邻数据集定义为:
∥x∥1=i=1∑∣X∣∣xi∣
这种情况适用于数据大小 n 是未知的情况。
如果数据大小 n 是已知时,也可表示为数据集 x∈Xn。
2、在 隐私的粒度 中提及了社交网络数据,或称为图数据库。考虑要对一个社交网络数据进行差分隐私保护,则有以下两种数据集粒度选择:
- 数据集 G,包含节点和边
- 相邻数据集 1 : G∽G′ 相差一个顶点(即个体)
- 相邻数据集 2 : G∽G′ 相差一条边(即个体间关系)
哪种选择会提供更好的隐私保护?
毫无疑问是相邻数据集 1 会提供更为强大的隐私保护能力。因为根据差分隐私定义,差分隐私算法保护个体存在的所有数据及该个体与其他个体的关系。从攻击者的角度看差分隐私算法提供的数据,就好像该个体从未出现在社交网络中,从关系网中被“抹杀”。显而易见这种形式能提供强大的隐私保护,但问题也随之而来。我们希望从社交网络中学习到有用的信息,但是去除单个个体所有条边可能导致无法学习到有效信息。
相对而言,对于边(关系)的隐私保护也能提供隐私性,但显然不如对于顶点(顶点)的保护大,但在对于某些应用来说是足够的。个体是显然存在的,更需要隐藏的是个体的关系网络。比如上下级关系,商业往来关系,主要联系人,亲密朋友等。在这种情况下,对边隐私保护足以保护敏感信息,同时使得数据得到更全面地分析。
在前文所述:
简单来说,如果我们承诺在每条边上具有 ε- 差分隐私,那么任何数据分析人员都不能得出关于图中 1/ε 条边的任何子集存在与否的结论。在某些情况下,大批社交联系人可能不会被视为敏感信息:例如,一个人可能没有必要隐藏一个事实,即他的大部分联系对象都是他所在城市或工作场所中的某个人,因为他的住所和住所他工作的地方是公共信息。另一方面,可能存在少数高度敏感的社会联系人(例如,潜在的新雇主或亲密朋友)。在这种情况下,边隐私应足以保护敏感信息,同时也能比顶点隐私数据得到更全面地分析。假设一个人的朋友少于 1/ε 个,边隐私将保护此类个人的敏感信息。
其中运用到了群隐私定理,假设每条边都是 ε- 差分隐私,我们可以根据群隐私定理得到,改变 1/ε 条边,则是的图差分隐私机制是 (1,0)- 差分隐私。
3、差分隐私宽松定义(近似差分隐私)
在前文中(定义 2.4)是差分隐私的宽松定义,定义中的近似项 δ 放宽了差分隐私机制要求。
下面先提及纯差分隐私定义(pure differential privacy)的自然底数 e 的作用。最后给出定义。
最初我们对差分隐私的定义要求,任何一个个体的数据差异不对最后产生的结果造成过大的影响。也就是说,如果我们考虑在一行上不同的任何两个数据集 x 和 y (即 ∥x−y∥1),则在 x 上机制输出分布应与 y 上机制的输出分布 “相似”。根据这个要求,很自然地就有了如下定义:
Pr[M(x)∈S]≤(1+ε)Pr[M(y)∈S]
注意:因为相邻数据集的概念是相对的,所以差分隐私定义都是对称的,即有:
Pr[M(y)∈S]≤(1+ε)Pr[M(x)∈S]
为什么要选择自然底数 eε 来替换 1+ε 呢?
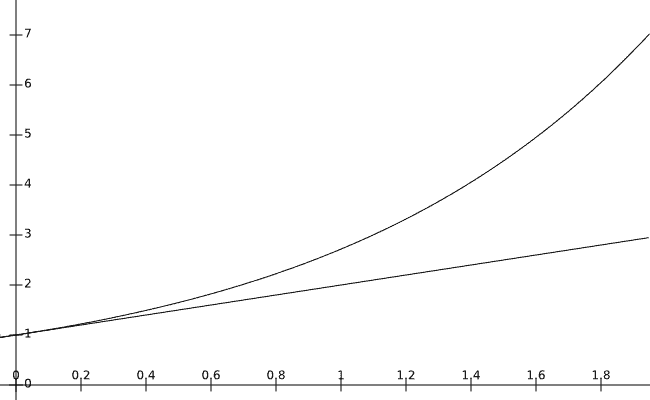
我们可以从上图两者对比看出,当 ε 接近 0 时,两者的曲线重合,使得在差分隐私参数小的时候,eε 近似 1+ε。同时这样选择,使用 eε 更方便,因为其在乘法运算下能更好表示以隐私预算相加(eε1⋅eε1=eε1+ε1)。因此才有了 纯差分隐私定义 公式:
Pr[M(y)∈S]≤eε⋅Pr[M(x)∈S]
但是,我们会发现,纯差分隐私公式是很严格的。该公式要求:即使概率Pr[M(x)∈S] 和 Pr[M(y)∈S] 小到可以忽略不计,但仍然要求对于每一个输出,两者的概率相差都应该很小,从而满足纯差分隐私公式。换句话说,ε- 差分隐私是绝对的。对于任何一对数据库,攻击者获得任何一个个体的概率信息都不能超过一个小数值。当在数据库中添加或删除一个人时,算法的所有可能输出都会以相似的概率出现。
相比之下,是否能允许机制中出现不满足ε- 差分隐私定义的场景?即:机制有可能以小概率输出在这个数据集的个体信息,借由这种小概率输出隐私信息(privacy)一定程度上获得机制的有用性(utility)。但是攻击者会有很小的概率可以由此知道所涉及的个体是在数据集中。
对这种不满足 ε- 差分隐私定义场景,我们用前文中所描述的进行概括。机制中可能出现这样一种情况:
值 M(x) 更可能由 x 产生。但是,给定一个输出 ξ∽M(x),可能会找到一个数据库y,使得 ξ 在 y 上产生的概率比数据库为 x 时的概率大得多。即,分布 M(y) 中的 ξ 的概率可以实质上大于分布 M(x) 中的 ξ 的概率。
可以看出,这种小概率事件就会破坏纯差分隐私定义,所以我们要引入一个近似项 δ 放宽强定义,使得更多的机制能满足差分隐私(如高斯噪声、二项式噪声等)
所以引出了差分隐私宽松定义(近似差分隐私)的定义形式:
Pr[M(x)∈S]≤exp(ε)Pr[M(y)∈S]+δ
这个定义本质上意味着那些破坏差分隐私的极小概率事件的发生概率 ≤δ。换句话说,可以将 (ε,δ)- 差分隐私解释为:机制至少能以 1−δ 的概率保证其为 ε- 差分隐私。
在引出这个定义之后,我们就会进一步探究数据集中有多少用户面临风险?可以使用参数为 (n,δ) 的二项式定律的期望值计算,每个用户都有可能发生这种情况的概率为 δ 。因此,平均而言,这将发生 δ⋅n 。
如果不想让任何用户面临风险,就要使得 δ⋅n 尽可能小。如果 δ=100⋅n1,则可以保证说 “以99%的概率,不会发生这种场景”。但是,如果 δ 相对于数据量 n 不是一个可忽略的函数的话,从泄露隐私的期望上看,当 n 增大时,机制将使一些用户处于危险之中。
4、差分隐私合成与群隐私
在前文提到了“差分隐私合成与群隐私”的概念区别,但是文中对群隐私没有进行一个清楚定义与表达,特别是没对带有近似项 δ 的情况进行说明。这边对群隐私概念做一个定义,并给予证明。并从直观上对两者概念进行区分。
【定义 群隐私(group privacy)】如果 M 是 (ε,δ)- 差分隐私,且对于所有成对数据集 x,y∈N∣X∣ 有 ∥x−y∥1≤k,此时机制 M 则为 (kε,k⋅e(k−1)ε⋅δ)- 差分隐私。
【证明】 我们使用混合参数进行证明。令 x0,...,xk 为 k 个数据,且 x0=x,xk=y。对于 0≤i≤k ,有 ∥xi+1−xi∥1=1(即两者相差为一行记录)。因为M 是 (ε,δ)- 差分隐私,则对于所有的 S⊆Range(M) 有:
Pr[M(x0)∈S]≤eεPr[M(x1)∈S]+δ≤eε(eεPr[M(x2)∈S]+δ)+δ⋮≤ekεPr[M(xk)∈S]+(1+eε+e2ε+,...,+e(k−1)ε)⋅δ≤ekεPr[M(xk)∈S]+k⋅e(k−1)ε⋅δ
【证毕】
从直观上来说,差分隐私合成是多个差分隐私机制的叠加。举个例子就如对一个数据集用不同的查询语句进行查询,这种查询语句我们就可以把它当作一种机制。这种机制(查询)的叠加造成了隐私损失 ε 与近似项 δ 线性增长。(定理 3.16)。
与合成定义不同的是,群隐私是指一个隐私保护机制(查询)应用于相差多条记录的两个数据集上。这个特点造成了群隐私的近似项如上面定义中提到的会发生很大变化。即使机制 M 是 ε- 差分隐私的,两者最后的隐私损失都为 kε 的情况下,其本质是不同。并且差分隐私合成可以将隐私损失进一步优化(定理 3.20),但群隐私无法做到。
这也解释了前文所述:
更普遍的说,差分隐私的合成和群体隐私不是同一回事,第3.5.2节(定理3.20) 中改善了机制合成之后的隐私预算退化程度(实质上改善了 k 因子)。但是这个定理不适用于改善群体隐私造成的隐私预算增大,即使 δ=0。